



In this article:
Data Classification means different things to different vendors and organizations. This article is intended to clarify the different meanings and share experiences in implementing classification as part of a successful Data Protection strategy.
Background
What Is Classification?
Depending on who you talk to, classification involves tagging data in some manner and/or applying human readable visual markings along with machine readable persistent metadata. Sometimes this even involves marking portions of a document with specific visual markings, often at the paragraph level.
Let us consider a classification schema, which is the definition of fields and values used to describe the relative sensitivity of information. This definition is universally applicable to two major categories of classification provided by cybersecurity vendors today.
Cybersecurity vendors mostly consider classification to be the recording of a value, typically in a database for one or more fields that classify the data. While classification almost always starts with a field for sensitivity, it often involves additional fields which classify the data related to categorization. In the broadest sense, classification can include medical, chemical, document, motion picture, and many more types of categorizations.
There are a select group of vendors and organizations who consider “full” classification to only be the application of visual markings on documents along with other capabilities. These visual markings pre-date the use of computers, when rubber stamps were often used on typed documents for classifications like “Top Secret”.
Today, the most pervasive mandatory and standardized labeling with visual markings is the U.S. government’s Controlled Unclassified Information (CUI). In general, an income tax return will be considered unclassified but does contain information which should be controlled, i.e. social security numbers and income for some private jobs. CUI originally started as Presidential Memorandum and then strengthened by a Presidential Executive Order (EO) 13556 issued November 4, 2010. Other government organizations who handled classified information including the Department of Defense, intelligence communities, and the Department of Energy (responsible for safeguarding nuclear information) have their own standards for labeling with respect to visual markings.
Currently, there is no private labeling standard for visual markings. Within the Department of Homeland Security (DHS) exists the Cybersecurity & Infrastructure Security Agency (CISA) which was established by the CISA Act of 2018. CISA uses a marking standard from the Forum of Incident Response and Security Teams (FIRST) called the Traffic Light Protocol (TLP). This is an excellent starting point for those considering implementing labeling. Some private organizations have adopted TLP as their first classification policy. This is a great start but should not be considered a one-size-fits-all approach to the first generation of an organization’s classification schema.
Classification solutions that apply visual markings often will also apply machine readable metadata which persists within the file or record. In this article, this combination of visual markings and metadata will be referred to as labeling.
However, times change, and the software industry is no exception. Today, when classification is mentioned, it is usually to record the category of information about a file, document, email, or structured data with a particular value for a given category. The category of sensitivity is nearly always included despite sometimes also being called just “classification.” Often, there are multiple fields for many categories and even relationships amongst these fields, so many Data Loss Prevention (DLP), discovery, document repositories, etc. will state features related to classification without any labeling features.
To really understand what a data security vendor is offering, ask whether visual markings and/or embedded metadata can be applied. There is a need to drill deep on embedded as many vendors will train their field facing engineering and account management staff that metadata is persistent, and it sometimes is. Ask if metadata is stored in custom document properties for Word to know for sure. If so, then it can be considered a true classification product which provides the most comprehensive handling instructions for both persons and processes running. This is not to suggest that solutions which do not do labeling are not classification solutions. Rather that there are degrees of classification available today among solutions offered and in this article the ”full” designation includes such labels. Full is within quotes as classification is subject to the eye of the classifier so to speak and therefore somewhat subjective.
A common analogy used to explain classification is package handling, specifically the contrast between human and machine readable labels put on packages handled by logistics firms. The visual markings shown below instruct human package handlers that a box has glass, should be kept dry, a specific end should be kept up, and it is fragile. A label with characters (not shown) often provide the required information to human package handlers about the next step or exception handling in the delivery processes.

Classification is amazingly similar to handling a package; instead, it’s about handling data. One of the most pervasive visual markings we are accustomed to appears in email signatures and typically reads something to the effect of “if you are not the intended recipient…” This is a form of visual marking instructing humans on how to handle the data. The need to handle data and provide visual markings was utilized from nearly the moment the email signature became automated. Today, we often see banners about an external recipient added to inbound email. This is simply another type of visual marking or labeling component.
An organization’s best classification capability can be attained by first assessing classification requirements and determining the categories or types of classifications needed. For example, many privacy regulations will expect support for right of erasure (RoE), retention period, right of processing activities (RoPA), and fundamentally a right to privacy.
A given jurisdiction may place additional regulations which supersede privacy to keep a record on file for a certain period, a minimum of 5 years for banks required to keep account information.
Evaluate solutions which, given the best information at the time, meet those requirements. Such evaluations act to verify claims from vendors, eliminate misunderstandings, and/or refine the understanding of capabilities prior to a purchase. Today’s classification requirements work to serve activities related to cybersecurity, data privacy and governance.
In summary, classification is about assigning categories and other information which act as instructions to correctly handle data.
How did Classification begin?
Greek Fire is the earliest cited example of classification to protect intellectual property in this article titled “OFFICE OF NUCLEAR AND NATIONAL SECURITY INFORMATION, HISTORY OF CLASSIFICATION AND DECLASSIFICATION” published July 22, 1996.
The First Continental Congress passed a resolution on September 6, 1774 that stated “Resolved, that the doors be kept shut during the time of business, and that the members consider themselves under the strongest obligations of honor, to keep the proceedings secret, until the majority shall direct them to be made public.” This is actually a great example of sensitivity drift, which often occurs with a control—or more accurately— a decontrol date.
Before the advent of commercial offerings with labeling, many in the intelligence communities within the U.S. government were using something called the Classification Management Tools (CMT). There are several commercial solutions that are “full” classification solutions with labeling and more. Today, dozens of cybersecurity solutions offer classification to assign a category or other metadata to data, whether structured, unstructured, or semi-structured.
Strategies for Data Classification
Trickle down effect with increased efficiency and efficacy
So much of what has been described except for Controlled Unclassified Information (CUI) is related to classified information, and even CUI is a government Executive Order (EO). It is only required in select private sector activities that interface with the government. So why consider or even use classification with labeling? Two reasons:
The first is an age-old trend that cybersecurity sophistication trickles down from signals intelligence as well as military activities. One of the earliest electrically based computers was the Bombe from the British Tabulating Machine Company used to provide decryption. This is not to suggest that whatever the spies do should be immediately adopted, rather that publicly available information around such activities is sometimes a leading indicator of cutting edge cybersecurity.
A recent EO (14028) on cybersecurity had eleven mentions in seven sections on Zero Trust. Attribute-Based Access Control (ABAC) can be deployed as an excellent Zero Trust architecture for unstructured data when the required attributes are present through classification activities on the object. See NIST SP800-162 for additional details on ABAC. Data will be increasingly protected through Zero Trust.
More importantly, you can increase the efficiency and efficacy of cybersecurity solutions with labels from classification. This will be described in more detail below in the section “Simplify and Unify”.
What categories should be considered?
The categories to use for classification should be such that handling instructions for persons and processes running can be determined. One of the most common fields used in classification is often called “Classification” and one of the most common values is “Internal”.
The category of sensitivity is so pervasive that using a field called “Classification” is synonymous with the sensitivity. The “Internal” example is simple. Anything classified as Internal should be kept inside an organization.
It is useful to categorize data a variety of ways. Perhaps by retention date or an organizational unit (a type of compartment) or with a hash representing some personal information which is linked in some manner to personally identifiable information. In a law firm, it is highly desirable to identify which legal matter a given file, document, or email is tied to as this helps with billing, confidentiality, and the overall business of practicing law.
For customers in the defense industrial base (DIB), intellectual property is managed and licensed for sharing through a Department of State Export Control Classification Number (ECCN).
Often in matters of national security and mergers & acquisitions, there is a de-control date where the sensitivity classification changes. For example, a press release about a large acquisition by a public company of another public company can considered material non-public information (MNPI) by the Securities and Exchange Commission (SEC) until it is published. Offer letters, quotes, performance reviews, purchase orders, checks, bank accounts, and many more all have a compartmental aspect to them.
To summarize, classification, PII hash, compartment, and de-control date are just 4 examples of categories which are likely needed to correctly handle data. There is a very good chance your business can benefit from more. Or you may decide to keep it simple to start with.
There may well be regulatory (privacy, payment card industry, etc.), compliance and legal positions within your organization who will mandate certain data handling practices. It is apparent that handling includes the areas of cybersecurity, privacy, governance and more. A classification schema is best established through the collaborative efforts of a broadly represented committee empowered to design. It often starts with a policy workshop and can take weeks or even months to finalize. A seasoned facilitator who is a classification expert can greatly accelerate and increase the efficacy of the schema.
Simplify and Unify
Machine-readable metadata is very much like the barcodes which are used by automation systems in logistics. Consider the barcode scanner attached to a point of sale (POS) system. Scanning is associated with an event that involves a person: the loader of the truck, the driver exiting the truck, the placement onto a conveyor belt which directs a complex series of changes in conveyors to another loader, the driver scanning a delivery versus leaving a note, etc. In all cases, the persons and processes can handle the package correctly. By coupling an event such as delivery attempt with a package identity, it also provides status of the package, i.e., no one available for signature.
Machine-readable metadata can direct different systems such data loss prevention (DLP), email, or storage repository to take action and log whether it involves a prompt to the user, an alert to security operations center (SOC), or otherwise. After leaving an organization but while still within its range of software-as-a-service (SaaS) solutions, a cloud access security broker (CASB) can control access, inter-application sharing, and activity tracking. Beyond that, a digital rights management (DRM) solution can provide continuous visibility, albeit in a more limited capacity than kernel level DLP agents.
Instead of each security solution operating independently to arrive at the correct handling instructions, the embedded metadata on unstructured information can provide such handling instructions. This can greatly simplify the administration of so many interconnected cybersecurity solutions. The impact of this simplification cannot be overstated as it cuts down on human error, reduces work, and because of that, creates an opportunity for existing staff to implement more sophisticated capabilities. For reasons of layered security or defense in depth, there’s value in keeping at least one system providing redundant classification.
In addition to simplifying administration, this unifying aspect of solutions speaking the same language will also mean a greater understanding of the data by establishing a common language for security practitioners.
Lessons Learned
Lesson #1: User Classification or not
If the user will be providing classification, you must have executive level sponsorship for this at the highest level in the organization where this will be taking place. It is imperative. In some organizations, user-driven classification is already a part of an employee’s workday, particularly in some sectors of government and the DIB sector.
In the Verizon Data Breach Investigation Report (DBIR), it was reported that insider threat is the number one source of data loss in the healthcare sector. From our collective personal experiences in healthcare, most would feel certain saying that privacy is on everyone’s mind. There are sectors where adding a little extra work, sometimes for user-driven classification, is likely to be both annoying and reasonable. In other words, there is enough understanding that it’ll be tolerated.
However, in positions where certain individual contributors, e.g. star players on a sports team, Wall Street brokers, or top account managers might object enough to such extra work that without executive level support, user classification is removed.
It is not enough to have a strong executive sponsor. An organization’s communications team and the human resources team will need to work to both create understanding and ensure it is embedded into the organization’s culture. Ask any potential service provider for a matrix of showing who is Responsible, Accountable, Informed, and Consulted (RACI) when implementing user classification. If one cannot be produced in short order and or does not include executive sponsor and communications, drill deep on their experience.
Labeling can identify data in nearly any manner. It may involve the user, two users, suggested to the user, guided user, or be completely automated with AI, policies, and traditional lexical expressions. Policy engines range from fixed frameworks with constrained options to building an object-oriented rule set with properties and methods, either of which can be chosen from canned solutions or extended to the limits of your imagination, e.g. disseminating a CAD drawing requires at least one additional approver.
Lesson #2: Crawl, Walk, and Run
Compliance and legal personnel are often responsible for an organization’s crown jewels of data. They make the rules, and they know the data, that data. This can range from in-depth data knowledge covering anywhere from 95% to more than 99% of the data flowing.
Conversely this means between 1% to 5% of the data does not have this same in-depth knowledge. If this remainder contains information vital to revenue generation, reputation risk, or many other high-impact scenarios, stopping such data can be the death knell for many cybersecurity solutions including classification, DLP, and CASB—just to name a few.
In the crawl phase, collect and analyze data. Learn and understand as close to 100% of the data as is possible and reasonable. In the Walk phase, begin to alert users about data handling actions that are planned to be stopped in the future and investigate when the user proceeds with those actions. The Run phase, which comes after this kind of initial data gathering is the time to start blocking. Do not block or be absolutely certain about blocking before the work of crawl and walk is complete.
Lesson #3: Classification can increase productivity and capability
Recall earlier how classification is used to assign values within categories. While it often starts with sensitivity of data, categories such as credit risk can be purposefully assessed using the same technologies, i.e. trainable machine learning.
It’s usually a straightforward exercise to identify a cohort of customers that represent a bad credit risk using an aged accounts receivable report. Coupling these customers with a data discovery solution to gather data artifacts from across an organization’s system is a means to build a corpus for credit risks. When a new credit application or an increase in credit comes through, an analytical model based on machine learning can give an indication of credit risk. While such activities are typically outside the scope of pure cybersecurity and privacy, it is without a doubt connected to governance.
Today, cybersecurity solutions around data protection will very likely provide services to all these areas. Publicizing how such solutions contribute to more than just controls will help the cause. Note, there is increasing concern about using AI to make decisions about individuals. In the above example, it was assumed the customers were businesses versus individuals.
Another great example of how classification helps with insight is automatic application of digital rights management (DRM). Imagine if this is done with every sales quote. Not only will there be visibility to see if, when, and for how long the intended recipient viewed a quote, but if it was forwarded and viewed by others. While not an absolute indicator, it is one factor that gives great insight into how interested a prospect truly is. DRM applied through labeling where users are abstracted from the DRM concepts has a much higher adoption rate.
Classification does not have to be about only blocking access, but it can also be about providing access to things beyond DRM. Some classification solutions enable access to collaboration resources through applying labels, out of the box. Others, through extensions, can be made to work with nearly any provisioning and/or access control system. This results in less help desk activity and more immediate service.
Lesson #4: Three Parallel Teams
Classification is hard. At the 2022 Innovate event in Arizona, Novacoast’s Michael Howden conducted a live audience poll amongst mostly CISOs, and gathered the results shown below.
If you remove Discovery from the answers, then Classification occurs almost 4 times as much as the average of all other solutions. With Discovery in the mix, Classification occurs just over 3 times more often than the average of all other categories of data security.
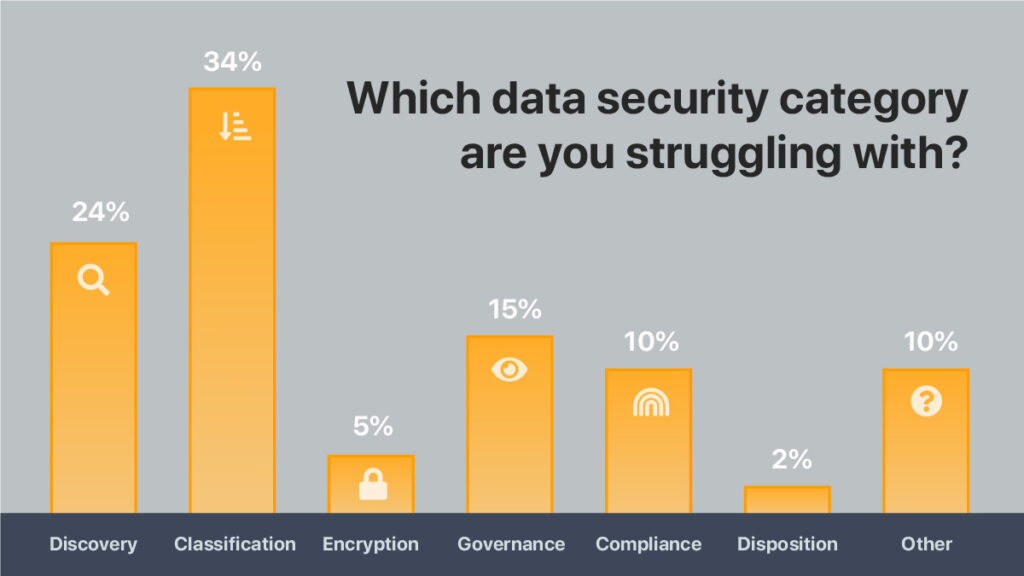
One of the biggest complaints cited is time to value. To accelerate the time to value, setup at least 3 groups at the kick-off meeting which are charged with:
- Organizational Policy
- Deployment
- Communications and HR
The Organizational Policy group should immediately begin work on a multi-generational roadmap which is consistent with crawl, walk, run concept described earlier. This group will need data to get beyond crawl. They will be designing and working on the walk phase while the other two teams are busy in crawl phase.
Deployment involves getting the software installed on the various types of endpoints including Windows, Mac, web, mobile, and any others. In deployment, the walk phase should be about two things:
First, getting as wide a deployment as possible, and second, deploying a policy which gathers data in the most minimally disruptive way. All software has defects, and such defects will surface in deployment. The sooner these are uncovered, the faster that resolution can be provided.
Communications and Human Resources (HR) or training is about letting people know how their endpoint experience will change. It is about advanced notice, a rationale for why this important, starting the long road of culture change, i.e. data security is now a hands-on activity for everyone.
Summary
In summary, classification is more abstract than most cybersecurity solutions, yet it acts as the strongest foundation to build upon. Everyone needs a little luck in cybersecurity and classification is great example of the harder you work at it, the luckier you will be.
The author
A Director of Security Services at Novacoast, Bill Brunt has assisted organizations the world over, both government and enterprise, with data classification and labeling solutions.