


Since the dawn of computer programming, the concept of logging events has been a foundational approach to solving issues with systems. Whether at an application or operating system level, the ability to view chronologically-stored log entries attributed to certain subsystems is a natural and very powerful tool for gaining visibility into the maelstrom of events that can occur in an otherwise opaque manner.
In the world of cybersecurity, logs play a very important role as a data source to monitor for network and system events that may indicate unauthorized or malicious activity. The SIEM as we know it is a tool based primarily on collecting logs and mining them for these events, with a scriptable layer to define triggers or alarms for stuff intelligence sources warn we should be looking for.
But is there a best way to perform logging? Of course. Tools like SIEM are only as good as the logs being gathered. This article will explain the case for thorough logging practices, what to do with the data, and the pitfalls to avoid.
Why Logging Matters
There are a few hard-coded reasons why logging matters or should matter to your business.
The Business Value
When logging is used correctly, it lets you be proactive or, at minimum, reactive to events happening in your environment. It provides the visibility that you need into what’s happening.
The Security Value
Of course, there’s tremendous security value in being able to see what’s happening in your environment, and if you didn’t already know that, you’re flying blind.
The Compliance Value
Sometimes your data logging is just for compliance. You’ve got to meet a checkbox, capture those logs, and you’ve got to store them for ‘x’ number of days.
Sources and Protocols
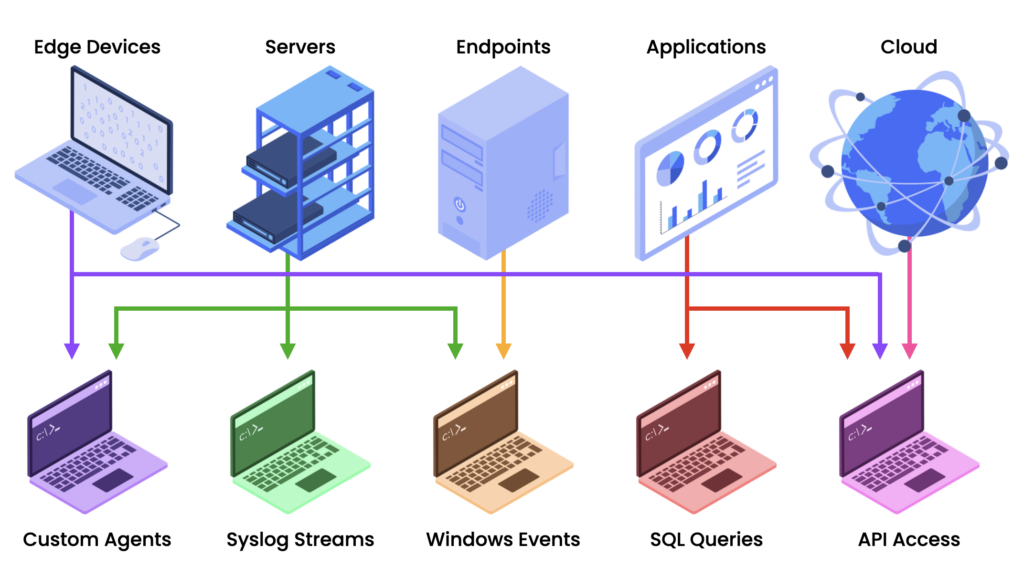
Log data often comes through multiple protocols with unique requirements. Each type of source can generate a wide variety of events in different formats.
Syslog is the lowest common denominator for streaming logs but there are also many API driven protocols and custom agents. And perhaps you don’t have a mechanism in place for sending logs for a particular purpose—you have to create your own method of ingesting logs by attaching them or sucking them out of a proprietary data store.
A logging infrastructure can be complex and can come in many forms, such as: Logstash, Syslog-NG, Rsyslog, FluentD, Kafka, NiFi, and many more including cloud-based solutions like Google PubSub, Azure Service Bus, and Amazon Simple Notification Service. There are many ways of getting log data out of an environment, including on-prem, cloud-based, and hybrid, but it’s ultimately the same exercise: moving it from one point to another where it can be analyzed and/or utilized.
Each protocol has different characteristics. Some protocols are data-rich, while others are basic and thin. Others will need to have data injected and have metadata added. Some protocols are made for real-time or streaming, while others are batch-oriented, meant to be extracted in bulk via query or file sync.
Some have time-series data or metrics such as instrumentation and telemetry data—performance oriented logs. The fundamental issue is whether that data is structured or unstructured, making the prospect of dealing with the myriad varieties of logs a complex endeavor.
Where Does It Go?
This question is important. SIEM/XDR is feature-rich but expensive. They are a powerful tool but without an unlimited budget, it’s going to be challenging. Why?
The amount of incoming data from log sources is continually expanding, which is a good thing for visibility if the infrastructure is up to the task. Too little data being captured is dangerous. There’s an optimal amount of data, and what is imported to the SIEM or XDR tools should be prioritized.
The term “SIEM” is a catch-all to include tools like Splunk, Elk, LogRhythm, Q Radar, and others, in addition to the cloud offerings such as Chronicle or Azure Sentinel Security Cloud. These products are critical to utilizing the mass of log data by providing some very heavy-lifting analysis and a configurable platform to monitor/alarm/alert.
Another place log data can go is a data lake or data warehouse. This can be used for lower value data which would be too expensive to store in a SIEM/XDR along with data that needs a longer retention period. With many breeches going undetected for extended periods of time, having access to historical data is critical not only for compliance purposes but also future investigations.
Sometimes, the data goes nowhere, and this can be by design if it’s determined to have no value. But if it’s going nowhere not by design, that’s a problem and should be solved. Important data containing valuable security events could be ignored. What can be done about this data that disappears without you ever knowing it and, ultimately, leaves you blind?
Maturing Logging Infrastructure
Reliability
Validation
Security
The first step in taking control of logging is to mature your log environment. You may have already completed some of these tasks, but let’s take a look at the entire voyage to make sure we know all points along the route no matter where we may be in the journey.
1 Reliability
Step one is reliability. If you can’t reliably get data from point A to point B without dropping any of it, your logging infrastructure isn’t working. You may not even know this is happening. If you’re experiencing a critical amount of data loss, it quickly becomes a nightmare where auditors get involved. That’s why it’s crucial to get a handle on data loss long before it reaches this stage. The environment must be designed for reliability.
When businesses look at their infrastructure and say they’re meeting their logging requirements and keeping up with logging traffic, that’s great. But what happens when new data enters the equation, or there is a spike?
What happens when a major outage event occurs, such as Facebook or AWS go down, resulting in a 30% spike in DNS queries? If your infrastructure can’t keep up with that new traffic it will blow up your environment and you’ll miss critical logs.
It’s critical that your logging environment can scale. Be aware of single points of failure. Not just switches, routers, firewall, load balancers, and servers, but also things you might not always consider, such as DNS.
All the products used for logging data can be fine-tuned to your environment. A common pitfall is sticking to the default settings which can lead to performance issues at scale. When tuned correctly, a single log collection and routing node is capable of scaling from capturing 10,000 events per second to one million events per second. To achieve this performance, tuning is essential.
2 Validation
Validating log data is critical because it ensures the data being collected is in actual consumable formats. It also lets you see which systems are reporting correctly and which aren’t.
Test how all your logs reach each environment, such as API-based logs. When the API token expires, will you be notified? How? Knowing when log data is being dropped is important.
It’s essential to get these processes in place. It often doesn’t even require new tools; it just requires fine-tuning the ones you already have. Ultimately, you want to create a redundant, highly-tuned infrastructure with things like buffering and failover mechanisms for when there is a problem.
Review and audit log data to get a feel for its contents. Look at the noisiest clients and ensure the data you’re getting is actually valid. You don’t want to pay for garbage data sitting in your logs and taking up space or corrupting important data.
3 Security
It’s evident that security is critical when it comes to data logging. Verifying that log data is encrypted is essential, but it may be a step that’s skipped because it’s a lot of extra work.
Typically, it’s easier when you’re using custom agents or a purpose-built mechanism to collect the data, but when you’re relying on Syslog or other protocols, you may be getting clear text. Sensitive data can reside in logs and should be encrypted.
It’s also a good idea to check what exactly is going into your logs. Consider the scenario where log types with different sensitivity levels are being combined into a single stream. In that case, you can inadvertently do some terrible things—confusing which log data is going where can turn into a nightmare very quickly.
Know what’s in your logs. Know where the logs are ending up and how they’re being used.
Clean Up Log Data
Filtering
Modifying
Visibility
One method for determining log type and what’s in the data is filtering. Usually, a filter based on pattern matching works for this purpose. The challenge is that data formats change, and the format you received today might be different tomorrow. To avoid miscategorizing a log when using this method, focus on filtering to verify.
Another method used is filtering by IP or network ranges.
Also, focus on reducing the amount of low value data. Make sure the data that’s being imported into tooling like your SIEM is the data you want to search, index, and analyze—not low value data that should go to your data lake if you have one. If you’re capturing data that isn’t being used, it’s a waste of an expensive resource.
Modifying
Sometimes it’s necessary to modify log data. For compliance or audits, you may need to retain the complete raw data log, and this is perfect data for data lake or cold storage data environments.
For SIEM environments, you can have different pipelines for wherever the data goes. You can use these to your advantage to filter on specific event fields. For example, if you have fifty event fields in a log message and only use ten of them, you can strip out the extra forty. Doing this can save some of your costs on your front end.
Verify that timestamps contain time zone information or are standardized based on UTC, but don’t try to correlate data that doesn’t have reliable timestamps – it’s a nightmare.
Visibility
A big issue in data logging is visibility. Having visibility into the health of the logging infrastructure is critical.
- Is traffic getting dropped?
- Are there resource spikes?
- Is the volumetric log flow monitor showing drops for any reason?
Take advantage of these metrics and, more importantly, suck them into the dashboards because these let you quickly see whether your logging environment is healthy or not.
Use your existing tools to build those dashboards – that reporting alerting – so that you know, proactively, that your environment is getting near capacity or reactively you get to know you’re dropping log data.
You can set up thresholds at whatever level you want for your environment.
Use these metrics for scaling based on time of day or resource utilization. For example, if you know you’re seeing resource spikes at certain times, you can scale up then and back when resource usage is reduced.
Best Practices in Data Logging
Isolate Log Flows
Audit Log Flows
Filter Noise
Standarize Data
Reduce Complexity
There are some best practices that can help if you work through them for your business. You may already be doing these, but let’s take a closer look.
Isolate Log Flows
From an architecture standpoint isolating most log flows can save some headache. While it might seem easier to use a single port or protocol for multiple log flows, complicated parameters are then required for filtering to identify what type of log it is.
By using specific, individual ports for things such as the firewall, windows events, switches, or however it gets broken it up, this accomplishes filtering at the network level.
The firewall team may not love the idea, but it’s very helpful. It’s also something that’s straightforward to implement when onboarding new log types, rather than going back and splitting off old ones which is a lot of work.
Eventually, this effort helps in cleaning up data logs. It also makes troubleshooting easier since specific traffic on each port points to a specific type of log. It will often significantly improve performance in many cases since many products use a single thread for each UDP socket and can’t leverage the available hardware.
Filtering Noise
Filtering noise makes a huge impact, but more significantly, it makes finding that needle in a haystack of security events much easier when there isn’t as much hay.
The more cleanup from the bottom up, the more it saves the organization in time, resources, and licensing. Leave the low-level data on endpoints, relays, on some lower value environment. It all doesn’t need to be brought up to the top.
It’s a common uninitiated approach to capture everything, but unless it’s required for regulatory compliance it can be filtered out.
Standardize Data
Timestamps are critical to get right. It’s crucial when indexing and parsing upstreams that your products are doing this right and without errors to avoid data loss. Those points of failure need to be monitored to ensure everything in your environment is doing what it’s supposed to do.
Reducing the amount of complexity in your environment is necessary to avoid additional problems.
Some log data will go directly from the source to a SIEM, XDR, or cloud solution, bypassing your log filtering and routing infrastructure altogether. And in other cases there are challenges when adhering to a standard protocol such as Syslog which is low level, and any metadata must be appended and reconstructed on the consuming end.
While introducing a custom agent can enrich data, it also adds some complexity and the potential for issues. It’s another point of potential breakage with requirements to manage.
Pitfalls to Avoid in Data Logging
Unreliable Protocols
Organizational Gaps
Lack of Visibility
Badly Formatted Data
Ignoring Log Data
There are numerous pitfalls when it comes to data logging. These are critical ones to avoid.
Unreliable Protocols
The UDP protocol can be problematic because it has no packet delivery confirmation as part of its design as TCP does. While UDP is slightly higher performance, any added overhead associated with TCP is worth the reliability.
It can be marginally easier to use if you’re using a load balancer and want to preserve the source address by spoofing them with UDP, but the issue of packet loss remains, with no means of alerting when delivery reliability is faltering.
Organizational Gaps
If it’s not well defined who’s responsible for handing off between two points, it will causes problems. Everyone focuses on the front end but, the fact is keeping the organizational visibility on everything beneath it is critical.
Lack of Visibility
You can’t know what you can’t see. It’s important to implement all the methods that report health of the environment in order to understand performance, capacity, and diagnostic information for when something breaks. Periodic health checks to verify operational performance are a must.
Badly Formatted Data
Garbage data. You don’t want it and don’t need it talking up your resources and wasting licensing expenses. It shouldn’t be filling logs up to create parsing errors and tying up system resources with weird binary streams that you can’t use. Go through and clean this stuff up.
Ignoring Log Data
Don’t waste all the time and effort invested in building a data-rich logging environment only to not take advantage of the value that the data provides. All the best tooling in the world is useless without each piece of the puzzle being tuned and verified for operation. Prepare the data. Make sure it’s being consumed by SIEM or XDR tooling properly. Then use it.
About the author
Dan Elder is a senior engineer with Novacoast specializing in security engineering, SecOps, DevOps, and leads the company’s Linux practice. He’s cleaned up some of the worst logging infrastructure disasters in industry history.

