


Here we are taking a look at hardware complexity, the operating system layer, and then application complexity together and talking about the challenges of securing these layers given the increasing complexity we face at every turn.
Hardware Complexity
What do we mean when we talk about complexity?
First, there’s this amazing proliferation of devices out there. You’ve got mobile devices everywhere; you’ve got IoT everywhere; you’ve got stuff in the cloud and on the edge—everywhere. You have more computing power and better network access than ever before.
It unlocks amazing new capabilities that can support your business, support you at home, or whatever it is, and that’s fantastic. Except that it’s also a little bit terrifying when you look at the complexity it adds.
It really leaves us feeling that we’re all alone in the dark when you try to understand what’s going on in a modern computing environment.
New Classes of Attacks and Devices
What do we mean when we talk about complexity?
First, there’s this amazing proliferation of devices out there. You’ve got mobile devices everywhere; you’ve got IoT everywhere; you have devices in the cloud and on the edge—everywhere. You’ve got more computing power and better network access than ever before.
It unlocks amazing new capabilities that can support your business, support you at home, or whatever it is, and that’s fantastic. Except that it’s also a little bit terrifying when you look at the complexity it adds.
It really leaves us feeling that we’re all alone in the dark when you try to understand what’s going on in a modern computing environment.
New Classes of Attacks and Devices
For example, a Pentium IV computer had 55 million transistors, and today, an Apple M2 Ultra has 134 billion transistors. Add to that all the supporting pieces of hardware around it, and they all add to that complexity.
Because of the additional complexity and physical limits that level of density introduces, things like Rowhammer are now possible. There are also many new classes of attacks that are possible. This is due to the miniaturization, density, and all the pieces of hardware that we’re putting together.
There are all these intersecting lateral movements you can have all within the phone sitting in your pocket. Do you know how many different chips are present in your phone?
We’ve seen some of the challenges that it brings, specifically when you look at things like Meltdown and Spectre that occurred in 2018. These rocked the entire industry because no one looked at CPU vulnerabilities in that way before.
Who would think that anyone would take speculative execution and turn it on its head? That you could go ahead and pull secrets out of the processor, change the execution flow, or do any of these other fun things?
Even in August, we saw the rise of Inception (RAS Poisoning) affecting AMD processors and Downfall (Gather Data Sampling) that impacts Intel processors. We’re still dealing with the problem of trying to pack so much functionality and performance into our CPUs and our hardware that attackers can take those same optimizations and turn them against us with disastrous results.
Yes, you can apply firmware updates—these microcode updates—at the OS level or at the BIOS level.
The challenge with that is that for many workloads, you see up to a 50% to 60% performance penalty. That’s really hard to justify on a business level and forces us to ask:
- Can I sustain that level of performance impact?
- Is that something I can tolerate from a risk perspective, or is that going to take down critical business assets?
Vendor-Specific Remediation
Design flaws are bad enough, and that goes back to developers being unintentionally evil, but sometimes developers are intentionally evil. That’s where you see things like malicious firmware that you have to watch out for now.
Firmware isn’t something people usually look at. The hardware itself is like a black box, and when you get firmware updates, if it’s something critical, maybe you apply it but often there’s a significant delay.
Look at some of these headlines; for example, last week, Republic of China-Linked cyber actors hid in router firmware. It sounds like some sensationalistic headline you might see from a vendor who is trying to sell a product. Instead, it’s a joint release from the CISA, the FBI, the NSA, and two Japanese security agencies.
The Often Overlooked
Malicious firmware distribution is happening out there, and while it’s not that common yet, what nation-states are doing today is going to trickle down to cybercriminals tomorrow.
It’s getting too easy to carry out these types of attacks at a layer you typically have no visibility into.
Dealing with firmware isn’t sexy and is often painful. You run the risk of bricking systems, but it’s important to look at these types of issues because attackers certainly are.
Your vendors may have ways of mass-managing firmware, and we must look at these things because they’re often overlooked.
So, what I did was I didn’t overlook them; I dug into them.
Fun With Firmware
Every vendor I investigated had similar problems, so this isn’t to pick on any specific one. I took apart some remote access controller executables that were just a firmware update, and there are two different versions here below.
The older one is on top, and a newer version is on the below it. Take the vulnerability counts with a grain of salt; there are duplicates. As you can see, these weren’t tuned in any way. Even on a remote access control on a network, which is hopefully segmented off, there are far too many critical vulnerabilities.
In here, I can see that one of the more important ones was an OpenSSL vulnerability. They did actually fix that; you can see that 351 vulnerabilities were resolved between one version and the other.
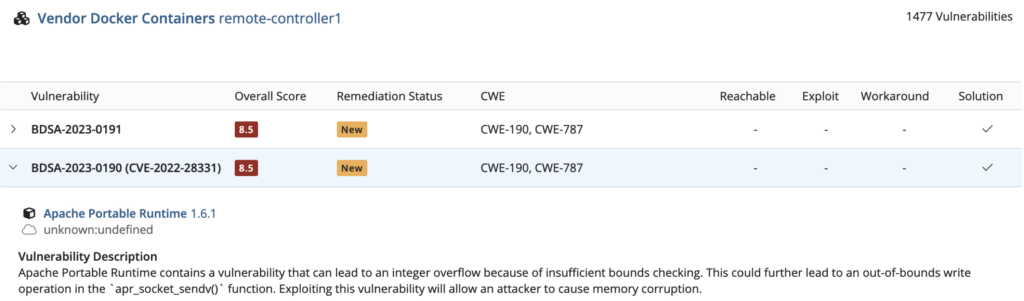
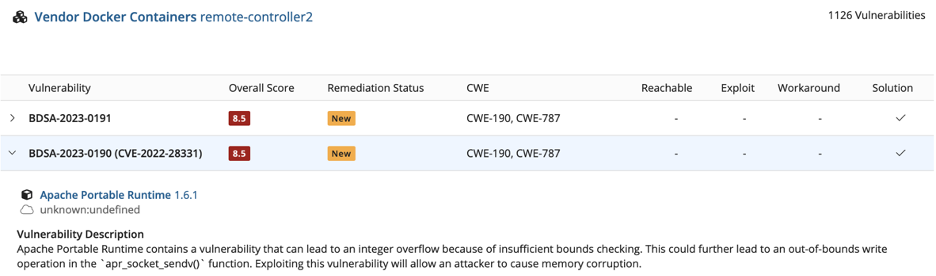
While that’s good progress, there is still a lot of bad stuff in there, including things like a six-year-old version of an Apache runtime.
I don’t want to have a six-year-old web service running for remote access control on my network that has known critical vulnerabilities. This is highly problematic.
All the firmware images I looked at had problems like this, so this isn’t to pick on any specific vendor. How many of us look at firmware images from our vendors? When you dig in, you find some troubling things.
Hardware Simplification
We really must simplify things. There are many basic things you can do, like looking at things like firmware.
- How do we track it?
- When do vendors release updates?
- How do we know that there’s an update?
- What tools are available to mass-manage it?
You don’t want to do this one by one; you want something that’s scalable. - Who’s responsible for doing it?
This often falls between groups, and when there are gaps like that, things get really scary.
So, there are some basic process questions and some tooling around that. The hardware is something you need to look at because attackers are, and the more they are leveraging it, the bigger the problem will be for you.
The hardware level is frightening currently. There is no model that can run software securely on untrusted hardware on an untrusted operating system. That’s just where we are right now. You could have malicious hardware embedded in your systems, depending on where your hardware is coming from.
You must watch out for many more things now, where before we just trusted the hardware. In today’s world, you can’t. It’s a little problematic.
Operating System Complexity
You may already be using containers, and containers are great. It’s an excellent strategy for deploying workloads. It’s almost magic. You get these tanky, self-contained workloads. They’re very survivable, and it’s the way we’re going to deploy all our applications in the future. Right?
Most of us are still stuck with a good amount of legacy monolithic apps, so it doesn’t work everywhere. With containers, you solve a lot of problems, such as patching. Instead of patching, you rebuild, redeploy, and avoid a lot of security controls that you needed at the OS level. So, it’s just the libraries left that support the application, which significantly reduces the attack surface.
With containers, it comes down to complexity and trust. Trust, but verify, is very important in everything we do with security.
Who’s really doing the verification on the containers you’re using?
Let’s dig in a little bit and see.
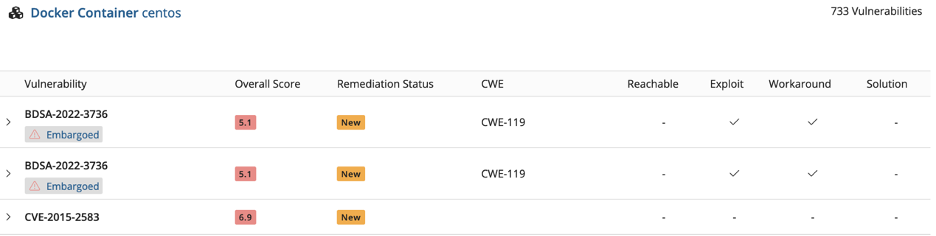
When you go to Docker Hub and take a look at the top ten container images, that are all vendor-signed. This is not to single out any specific vendor; every one of them has known critical vulnerabilities. Keep in mind that these are not new, unknown vulnerabilities; they’re known ones that the images are still shipping with.
That’s very worrisome.
These are the core images that you then go and build your applications on top of, thinking that this is the latest and greatest version, so it must have all the latest security and bugfixes. The vendors signed it, so it must be great; it’s not.
Our entire industry is building things on this insecure foundation. Look at these images; for example, we see things like remote executables and zero-click RCEs, and that’s really bad. You don’t want to see these in your image. Maybe they did have a justification for that; maybe this software is rarely used, or maybe it requires a difficult exploit chain.
Still, if you’re putting your application on top of that and you don’t know those things:
- What if your application uses that code?
- What if your application relies on those capabilities?
Your application is now vulnerable to a layer that you have very little visibility into. It’s not like the release notes for the container say, “Oh, by the way, we’ve got vulnerable software.” You don’t even know that what’s there is problematic. These are the types of things that you really need to dig into and see because it’s not just one or two containers; it’s every single one out there.
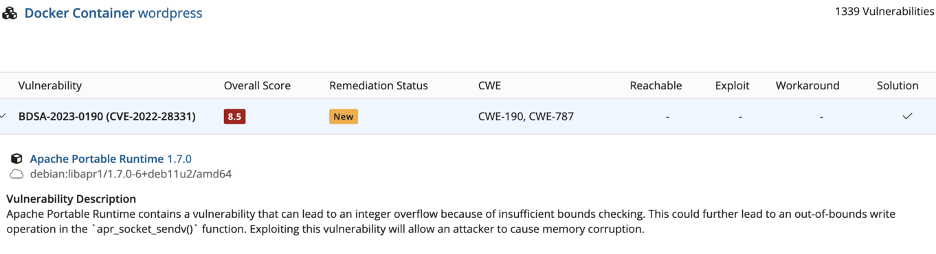

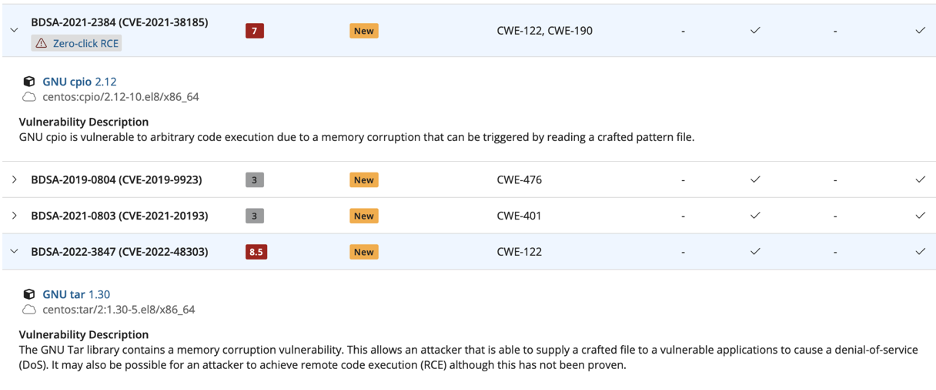
Here are a couple more that may be difficult to read, but here’s WordPress, for example. Does anyone expect WordPress to be secure? No, but you expect the application itself to be insecure. You don’t expect the container to include a vulnerable version of Apache, for example. Those are things that should be easy to solve.
The same challenges are present with a database container. We expect it to not have vulnerable versions of OpenSSL. We all went through a hell of a heartbleed. Why would you include in your latest and greatest vendor-signed container vulnerable versions of OpenSSL? The reality was that every single container had problems like this.
Again, those vulnerable counts include a lot of duplicates. The goal here was just to go in, find what’s in there, to get some visibility into a layer that people don’t look at. Most of us just look at the application on top, but not the container level below or the firmware below it. When you’re missing that, there’s a whole layer of risk that you don’t see, and that’s a big gap that must be addressed.
The Challenge
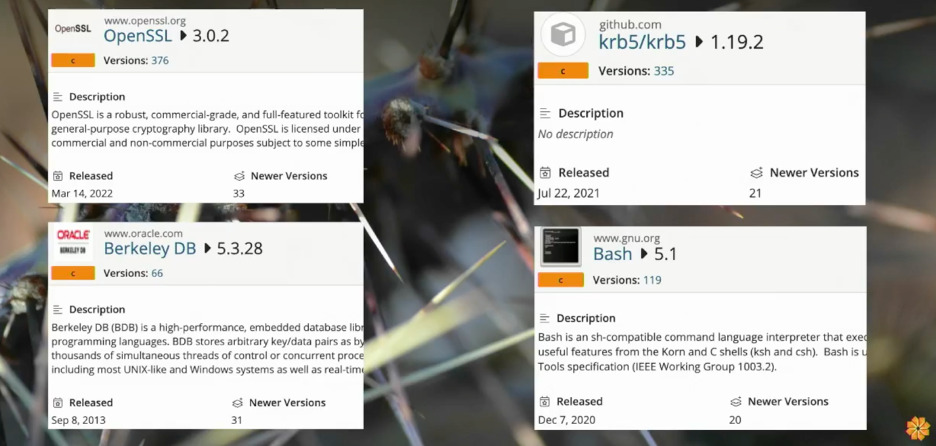
So, the fundamental challenge is that we build solutions with old software. That’s not necessarily bad, but a lot of this old software is vulnerable, and if you’re not checking to see if it’s vulnerable, that’s a blind risk you’re accepting. You can use new software, but that’s more regression testing; you also need to go through all these other pieces. You could still be introducing some new and unknown vulnerability, so it’s not foolproof. The further down the top 10 list of container images you go, the uglier it gets, and things like including vulnerable versions of OpenSSL—a year old doesn’t seem that bad, but there are 33 newer versions.
Using Berkeley DB as an example, we’re still using a 10-year-old version, and that’s primarily for licensing reasons. There are critical vulnerabilities in there, but for licensing reasons, everyone still uses this old version. That may be a valid business decision, but does anyone who’s using that software know that?
When you’re building on top of that container, do you realize someone else has made that security decision for you, or is that something that’s just there that none of us knew about?
Again, this isn’t specific to containers; all our software is developed this way. I just wanted to illustrate this because containers are one of those things people don’t dig into nearly as much as they do with traditional operating systems.
The Reality
Containers don’t magically solve all our problems, but they do have some excellent benefits, and that’s nice, you know. If you’ve got a fully containerized environment, that’s fantastic. Now you’re cooking, and you’ve done a lot of things right, and it’s not an easy process to get there.
There are a lot of excellent advantages to running things containerized, so by standardizing deployments, you can reduce those support needs and avoid misconfigurations. There’s all that methodology around rapidly rebuilding and redeploying, which lets you react to security incidents much more quickly as opposed to having to go through and audit everything else. So, it’s also a much better way of doing things from a business standpoint; you can roll out new versions and new functions, support your line of business, and support your customers much more quickly with that type of architecture.
Then, when you really design things for containerized workloads, you’ve got microservices, architectures, and all these stateless apps. It’s an excellent way of minimizing that attack surface, so you get good, consistent deployments with really good isolation between them.
Not to beat up on containers because they are good, but as you move to this containerized world, a lot of the existing controls, processes, and solutions that you had for managing your application workloads need to evolve and change with it.
You’ve got new things you must look at, such as container orchestration:
- How do I do lifecycle management for my containers?
- How am I doing vulnerability scanning?
- How am I looking at the network isolation of my containers and looking for all those types of controls to see what my containers are doing and if they’re doing the right things because a good application does what it’s supposed to and nothing else?
- How am I enforcing that and nothing else, including my container level?
You need some new tooling for that. Most likely because those OS-level controls that you previously had that looked for the interprocess access control and communication have changed. They now look for what’s going on. You need that now in the container world.
So, you can’t just move there automatically and find everything to be solved, but it is a better place once you get there. The OS layer is getting better; it’s not all the way there yet, but we’re making progress.
Software Layer
Containers don’t magically solve all our problems, but they do have some excellent benefits. If you’ve got a fully containerized environment, that’s fantastic. There are a lot of excellent advantages to running workloads containerized, so by standardizing deployments, you can reduce those support needs and avoid misconfigurations.
The methodology around rapidly rebuilding and redeploying lets you react to security incidents much more quickly as opposed to having to go through and rely on cumbersome and error-prone patching processes.
It’s also a much better way of doing things from a business standpoint; you can roll out new versions and new functions, support your line of business, and support your customers much more quickly with this type of architecture.
Then, when you really design things for containerized workloads, you’ve got microservice architectures and all these stateless apps. It’s a really good way of minimizing that attack surface, so you get good, consistent deployments with better isolation between them.
Not to beat up on containers because they are good, but as you move to this containerized world, a lot of the existing controls and a lot of the processes and solutions that you had for managing your application workloads need to evolve and change with it.
There are new capabilities you need to properly deploy, manage, and secure your container environment:
- How do I do lifecycle management for my containers?
- How am I doing vulnerability scanning?
- How am I looking at the network isolation of my containers and looking for all those types of controls to see what my containers are doing and if they’re doing the right (or wrong) things?
You need some new tooling for that. Most likely because those OS-level controls that you previously had that looked for interprocess access control and communication have changed.
All the various agents you used at the OS level to provide those security controls likely don’t align with the needs of a container environment, and the business and IT processes for managing them also need to evolve.
Software Layer
We looked at hardware, and we looked at some OS solutions. Now we’re going into applications themselves and really the AppSec side of this, and you’ve heard this multiple times already, but it’s something we really must reiterate repeatedly since there’s all these abundantly available open-source and commercial frameworks and platforms you can build on and your business can deploy applications like never before.
You can have these amazing, incredibly productive, and powerful IT solutions developed and deployed faster than ever. The reason you can do that is because you’re depending on this vast web of software that you don’t really know anything about.
Developers can include something that depends on something else, which then depends on something else. Before you know it, you’re bringing all these layers of dependency into your application to the point where it’s not your application anymore.
You’re only creating this little piece on top of all of it, and the entire foundation of your application was written by someone else.
- Do you trust them?
- How do you validate the code?
- How do you ensure the code is actively maintained?
It’s a very risky business proposition to have all these layers of unknown software in your environment. Hopefully it’s written by someone in their free time just because they were a nice person, but what if it’s not or that person no longer maintains it?
How easy is it to inject something malicious or just unintentionally make a catastrophic mistake that opens your application up to a horrible vulnerability? You can’t really assess the risk of that if you don’t know what’s in that code. You need tooling to at least understand what you’re working with.
From a business standpoint, the ability to build applications on top of all these layers is a powerful force multiplier. From a security standpoint, though, you don’t have good visibility into what’s there, so let’s look at some code.
Software Development
I looked at some versions of OpenSSL and a sample Java Web App just to dig into them and see some of these common coding practices that lead to vulnerabilities.

This is where developers are unintentionally evil, hopefully. Following secure coding practices is difficult, particularly when the choice is between meeting deadlines or performing security audits. When we look at these samples, there are issues like SQL injection attacks from unvalidated input, resource leaks, or any number of different things they could have done in this code that then allow potential exploits.
It’s important to have tools like this in your software development lifecycle to be able to catch these types of issues as early in the process as possible. Trying to find these types of coding mistakes years down the line after a product has been shipped and compromised is massively more expensive than finding it the first time a developer commits their code or builds the product. Just finding anyone on the development team who knows and understands code that was written years in the past and can track down the issue is a significant challenge let alone having to go through regression testing and getting patches out and deployed to all your customers.
If you can do this type of work as close as possible to when the code is being built, you’ve saved yourself significant cost. The shift left methodology means it is much cheaper to find and fix the security flaws as you’re developing the code rather than long after you have shipped a product.

The fundamental security challenge is we do not have good visibility; we think we do, and then it turns out we are blind. Our traditional solutions for vulnerability management don’t look at these layers.
For example, this is a view from the underground of old Seattle. A hundred years ago, that was probably much clearer and gave us all the visibility we needed. We don’t have that today.
New tools and processes are needed to dig into application security at a much deeper level and automate as much as possible to avoid the gaps that lead to security failures. Our traditional solutions aren’t designed for these types of attacks, but as they increase, so must our defenses mature. The age-old game of cat and mouse goes on, with this being yet another area of IT we must add to our list of threat vectors.
Like most things in cybersecurity and IT, the great news is that you still must handle all the access controls and all the security tooling you’re doing today, but now we’re going to add more on top. That’s what we do. We keep adding more to your to-do list, and unfortunately, that’s where we are.
Without the visibility these additional tools and processes provide, you can’t accurately assess risk in the environment. If you can’t assess risk, how are you supposed to communicate that to leadership?
Every organization will be at a different point on their AppSec maturity journey, but as a starting point, here are a few of the key pieces needed by most security programs:
- Software Composition Analysis (SCA)
- Static Application Security Testing (SAST)
- Dynamic Application Security Testing (DAST)
Software Composition Analysis tools are useful for determining all the various dependencies of a piece of software, the version of each dependency, and then checking them for known vulnerabilities. Some tools can also determine the software components that make up binaries and can even give good estimates of the version of each component depending on the vendor, which gives a lot of added insight into what traditionally has been a black box that requires trusting the software vendor to secure it. Having visibility into whether the binary (or source code) you’re working with was built using vulnerable versions of third-party software is essential for understanding the risk of incorporating that software in your environment.
There are many examples of how difficult it can be when vulnerabilities are discovered in commonly used software libraries like OpenSSL or Log4J. By proactively scanning your own applications or third-party applications you will know instantly when a major vulnerability is discovered what your exposure is. Many SCA tools will also create a Software Bill of Materials (SBOM) which your vendors should be providing for you, and you should be providing your customers so that they know exactly what software will be running in their environment and the version of each piece. This type of proactive discovery and inventory tracking significantly mitigates the impacts of catastrophic 0-day exploits when you don’t have to frantically search for which pieces of your environment are vulnerable, you’ll already know and can skip discovery and go right to mitigation. Static Application Security Testing (SAST)
SAST tooling is useful for analyzing source code for common mistakes that lead to security vulnerabilities. While secure coding practices will minimize the chances of developers introducing security vulnerabilities into the codebase, they can’t entirely eliminate them and most organizations can’t afford full secure coding practices anyway. Leveraging SAST to find these vulnerabilities as quickly as possible allows an organization to fix them faster, before they become serious.
Integrating SAST tools into your CI/CD pipeline correctly generally isn’t hard, but working with your development team to effectively utilize the results is important. Adding more work to already overburdened and behind-scheduled development teams can create friction and frustration, so it’s important to purposefully deploy these types of solutions in ways that support both security and business objectives but also ultimately make your developers lives easier.
More advanced SAST offerings can also be very effective at finding more complex coding mistakes that escape manual code reviews or other development practices and can effectively prevent the type of cascading security failure that can require significant rework if not mitigated before other layers are added on top.
Dynamic Application Security Testing (DAST)
Where SAST analyzes the source code, DAST analyzes the finished product. DAST tools can be effective against compiled code, webapps, or other situations where you may not have visibility into the underlying code or need to ensure other layers of the application can withstand common attachment vectors. By stress-testing input validation in an application and performing other injection-level attacks against it, potential vulnerabilities can be identified before attackers discover them.
While many applications leverage exposed APIs and integration with third-party software and systems, it’s important that each layer of that application be validated against common penetration techniques, which is why DAST scanning can be so important. Even if you don’t have visibility into the code, you can gain better visibility into how vulnerable an application is.
The first few times people use these tools, there is a lot of work required because that’s when they discover they’re including some really old software in their product and need to go through and fix it before shipping the next version. You don’t want to give an SBOM showing you’re including 10-year-old vulnerable software, so it’s very useful for building that trust.
It’s also critical, as a consumer, to get that information from your vendor. They need to be providing you with this, because otherwise you have to blindly trust them to run something in your environment. When deploying a new application, it’s important to ask questions like:
- Do you know what it’s doing?
- Do you know what it’s built on?
- Do you know if it’s vulnerable?
- How do you assess that?
- Does my vendor give me an SBOM?
- How mature is their AppSec program?
- How do I validate that?
You need these new ways of doing software development. Following this to effectively understand what’s running in your environment, what’s the risk, and whether it’s worth it.
Entire Supply Chain Is Vulnerable
So, to borrow a phrase from CTO Adam Gray, we’re cursed. Our entire supply chain is vulnerable—at the hardware level, the OS level, and the software level. Everything’s bad, right?
The problem is that we build IT like we build our cities. We’ve got these layers and layers of cruft that we’re building on over time, and no one’s really looking at it.
They’re not looking at the known vulnerabilities. They don’t know what’s down there. We’ve got all this complexity beneath us, and each layer of that foundation is just full of cracks and full of holes. We don’t have good visibility because many of our tools aren’t meant for looking at those types of things, and that’s very frightening.
When you think about it, would you drive a car that had dozens of recalled parts that are known to fail under certain circumstances? I wouldn’t want to drive that car, and yet that’s how applications are.
We know they’re riddled with holes. We know our hardware has all kinds of vulnerabilities. We know the OS is vulnerable, and we can’t keep up with the constant patching just for the known vulnerabilities.
That is our car, and so that’s a very frightening proposition because we’re responsible for providing these services as securely as possible.
How can you adequately do that?
These supply chains are very vulnerable, and the attacks are catastrophic. Look at MOVEit. There were over 1000 organizations and over 69 million users that were impacted. The SolarWinds breach has impacted some of the most secure organizations in the world.
These are very catastrophic things to recover from, and yet we still can’t get patching right.
To accurately understand your risk, you need better visibility, and these are some of the tools that are critical for that.
The Author
Elise Manna-Browne is an expert in threat intelligence, threat hunting, phishing, incident response, penetration testing, and malware analysis. She is the VP of Emerging Technologies at Novacoast and leads their cybersecurity incident response team.
