



Over the last year, he reviewed how and what he was doing, and while the principles remain the same, his approach and execution have vastly changed.
Read on to learn more about his new approach that he shared at Innovate 2022.
The Standard Vulnerability Management Lifecycle
This chart is undoubtedly familiar to everyone and is a Vulnerability Management Lifecycle. While some businesses may have one or two additional or fewer steps, we’re all looking for the same thing: holistic visibility.
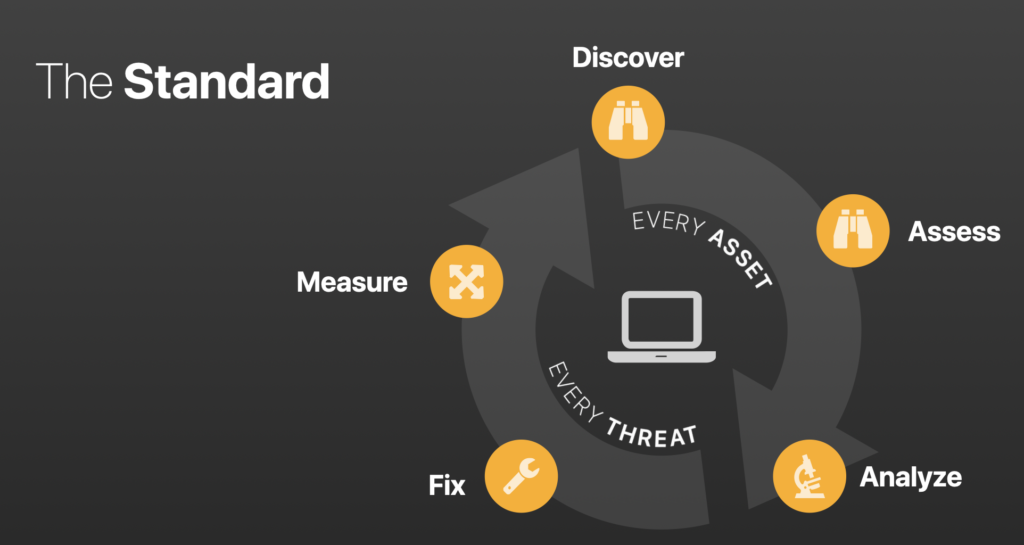
- We want to ensure we scan all assets for vulnerabilities regardless of system type, operating system, computing environment, etc.
- We want to ensure we’re interrogating and assessing those hosts as thoroughly as possible and that we’re authenticating wherever and whenever we can to enumerate all the vulnerabilities on any system.
- We want to analyze that data, and, generally, we want some predefined approved set of criteria where we prioritize those data to determine what needs to be remediated first and to address those vulnerabilities posing the most significant risk.
- We want to report on those data and get them to our counterparts in the IT Operations side of things to fix them – applying patches, updating software, and fixing misconfigurations. Those folks, essentially data customers, need the correct data in the right format to action it.
- We want to measure our success rate and the efficacy of the program and share this with senior leaders so that they can make informed business decisions about where they need to invest resources to improve deficiencies in the organization.
People, Process, and Technology
More often than not, we see that it isn’t the tooling holding customers back in this area. We don’t walk in and say “oh, you’re using Qualys, and that’s no good. You need to be using Rapid 7 or Tenable, and then you’ll be fine.” That’s not how it goes.
It’s not the tools holding us back—it’s roles, responsibilities, and, ultimately, process problems. Aside from optimizing, tweaking, reconfiguring, or possibly redeploying, you should be asking:
- Do we have well-defined processes?
- Do we have processes at all?
- Do they need to be refined?
- Are they running efficiently?
It’s clear to see these individuals on one side are highly trained, well-disciplined types who understand precisely what their role is in a specific operation and, tools aside, should things go to seed, they not only have the training but also ingrained policies on what to do in each situation.
It’s completely contrary to the folks on the other side, where no tool known to man will make them succeed at anything except a very common problem.
Working with customers all the time, we help them sort out steps 1 -3 on the lifecycle wheel.
- Maybe we can redeploy existing tooling to increase visibility or diversify the type of sensors used so more endpoints are seen in different computing environments.
- Maybe we can work on how thoroughly a business interrogates its systems or start tracking authentication and failure rates.
- Maybe authentications are successful, but we’re failing to elevate privileges.
- What do we do about tracking vulnerabilities on endpoints affecting assets that miss scan cycles?
- Maybe by defining or redefining remediation prioritization criteria.
- Perhaps it needs better reporting – and maybe reports are going to the right people, and that’s the roadblock.
It isn’t any of these, and you can see the big red glass ceiling.
At some point, we hit a wall, and it’s frustrating because you know why the trend lines aren’t going down.
It isn’t because we don’t know what vulnerabilities are out there. We know we have them, but the wheels somehow fall off the wagon when those reports go out to different teams responsible for other groups of systems using various tools. It is essentially a clunky process.
Why do we care?
Paradigm Shift
Aside from the trend lines not going on and just having that awful feeling of people from the senior leaders coming and asking what is wrong with the vulnerability management program. And it’s like, I don’t know. And I mean nothing save for the fact that you’re just awful at patching.
Another thing that is rising is the speed at which CVE IDs are introduced, and they’re coming out at a high velocity, as we’re sure everyone has noticed. Even more concerning is the recent increase in the speed at which attackers can weaponize exploits against those vulnerabilities.
The old methodology, for many reasons, is too slow.
It’s not that it’s wrong. It’s not that we no longer care about holistic visibility, authenticating to our hosts, enumerating all the vulnerabilities, reporting on them, or visualizing that data.
It’s just that paradigm of using vulnerability assessment tools. In some organizations, they have many of them and hand off that data to other teams that frequently use SCCM, Manage Engine, and various patching tools, depending on the operating system being targeted.
It’s inefficient and slow, and ultimately, we’ve found it to be too unsuccessful.
So, what can we do?
Are tools a solution? No.
We can consolidate our people and our processes under technology. We can get thinner. We don’t need as many tools – particularly on the patching side, the software management side, and the distribution side. We can eliminate many of those endpoint agents and more.
It’s time to rethink risk-based prioritization. Is looking at vulnerabilities like characteristics specific to the vulnerabilities and specific to the assets that are affected a bad idea? No.
Knowing the most critical and exposed systems is imperative, and he says he’d probably implement prioritized patching on those before worrying about anything in a dev-test environment, etcetera.
Is that the best philosophy? Adam touched on this in his talk during Innovate 2022. Should we focus on what systems are missing patches and which are running out-of-date software?
65 to 70% of breaches are not from the latest, greatest, sexiest zero-day, and they are from a missing patch. That’s an all-encompassing statistic. So consider an old version of Chrome to be a missing patch.
Reassess risk tolerance. It’s sort of interesting that there isn’t a single definition point to explain this, and it’s more a less staying mindful of the way we accept risk when it comes to devices that are missing patches or running out-of-date software or why we are so slow to respond to patching those systems.
One Year Later
Here are some observations over the past year.
With just opportunity and customers willing to be our Guinea pigs, this data represents trying a different approach on the tooling side. It includes network scanning for vulnerabilities, analyzing, prioritizing, reporting, sending it over, and seeing what happened at the end of a maintenance cycle.
The organization supported could do this by themselves by using a multifunctional endpoint agent approach so that one agent could do multiple things. Everyone knows the products out there that scan for vulnerabilities. They can tell you exactly what software and version are running on every endpoint, what patches are missing, and about a million other things.
Customer A
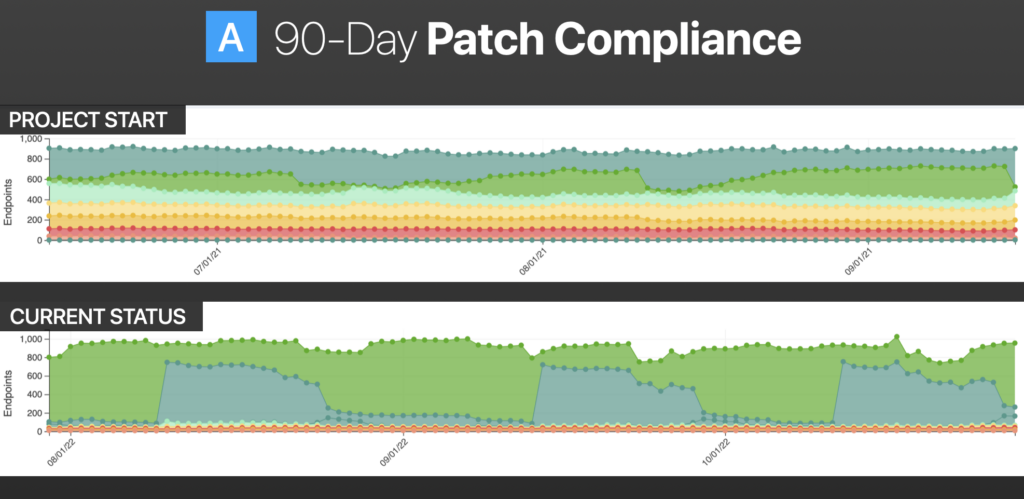
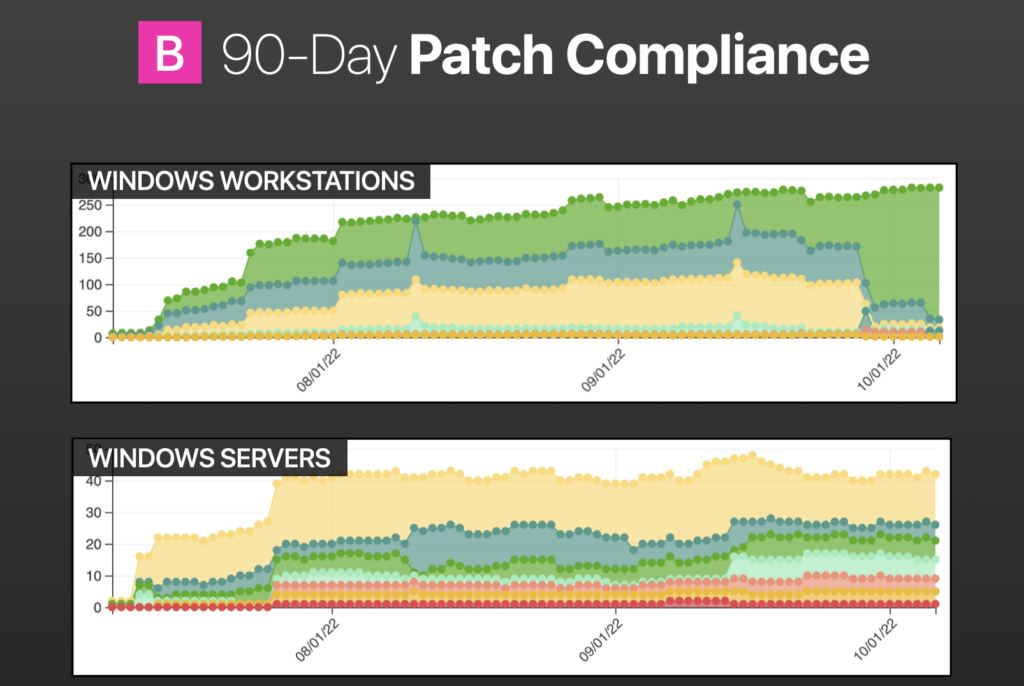
This customer is a mid-sized multinational chemical company to give you the industry vertical and sort of side-by-side at the start of the project. The top image shows where we were in terms of endpoint compliances.
The green points in the middle are compliant endpoints. That is, no missing critical or important patches and no superseded patches with a release date of more than 30 days.
All the colors at the very top are missing 1 through 5, and then every deviation thereafter, 6 to 10, and then 11 to 25, and so on. The redder parts are the really bad ones. Those are missing the 100 or more.
The bottom image shows where we are now. You can see that any on the bottom are pretty much machines that must be reimaged, but there are some peaks and valleys that we would expect to correlate with Microsoft Patch Tuesday releases, so just an overall improvement in compliance.
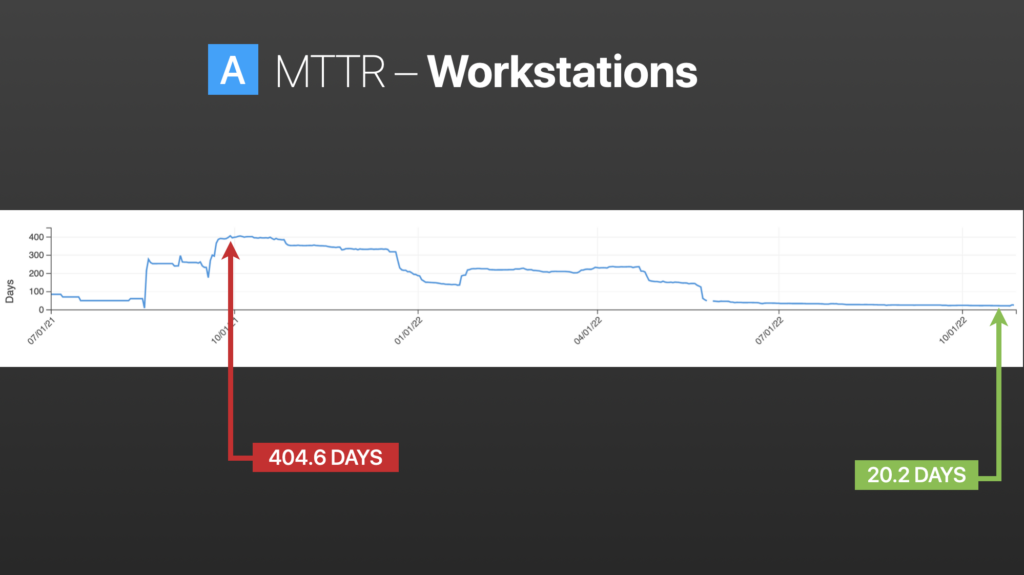
Patching
It’s been established that most breaches are happening at the endpoint, and specifically the workstation. On the far left in the above image you can see where we started with onboarding. We got a clear data set over 400 days and continued to trickle down, to the point now where we’re on a cycle under three weeks.
We’re getting close to enterprise patch compliance and positioning ourselves to sort of snipe at the stragglers. These include the endpoints that need to be reimaged, don’t have enough disk space, or ones that aren’t being rebooted.
Software Updates
Again, in this image, we started on the far left, where the average time to update endpoints was 105 days.
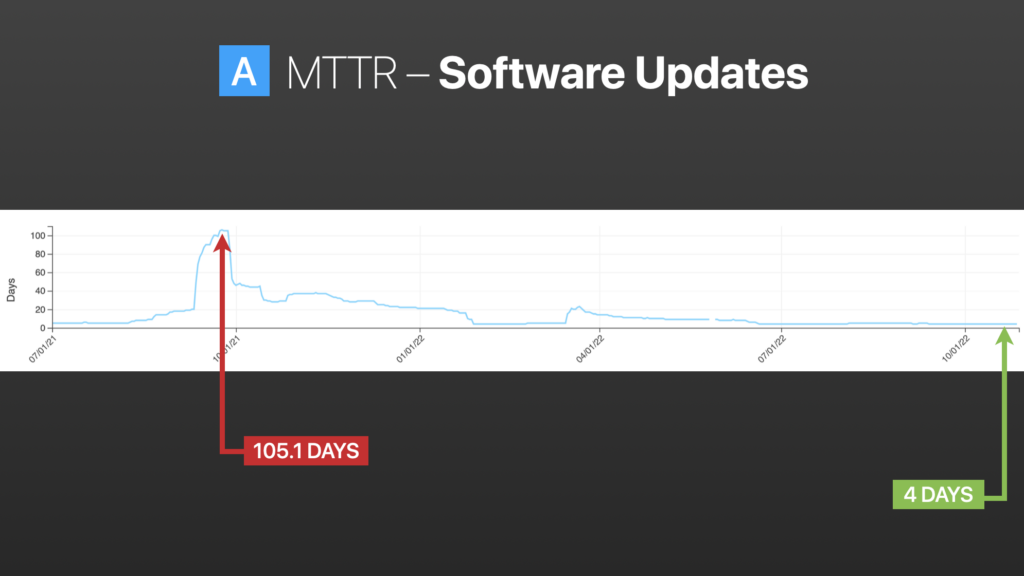
As we go down, there are some crests and troughs there. That represents some successes—we did a good job with low-risk updates such as browsers.
Then we tried something else, like Adobe apps, Webex, and chat applications. Now we’re down to an average time to update of 4 days.
Customer B
This is a smaller customer that just started. We’re showing this because it’s broken down in a different way. Workstations and servers.
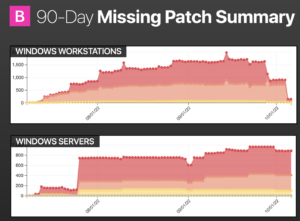
Workstations: this is what we decided on to collectively utilize this new endpoint-based paradigm.
On the bottom, they retained that they were going to use the old methods to patch servers because… servers are scary. This customer said: “Scott, you don’t understand—there are a lot of considerations.” That’s why I’m here!
Back to the chart: the dark red areas are critical missing patches, not vulnerabilities—missing patches. The light red denotes important, and the yellow medium.
If you look on the far left of the chart, you’ll see the onboarding, you’ll see we were running some tests, and then after about a month (at the end of October), you’ll see the amount of historical debt we reduced and the number of missing patches we were able to apply. You can see it side by side with the servers, a much different picture.
In the image on the left, it’s sort of the same thing, just endpoint compliance. We changed compliance in literally one month.
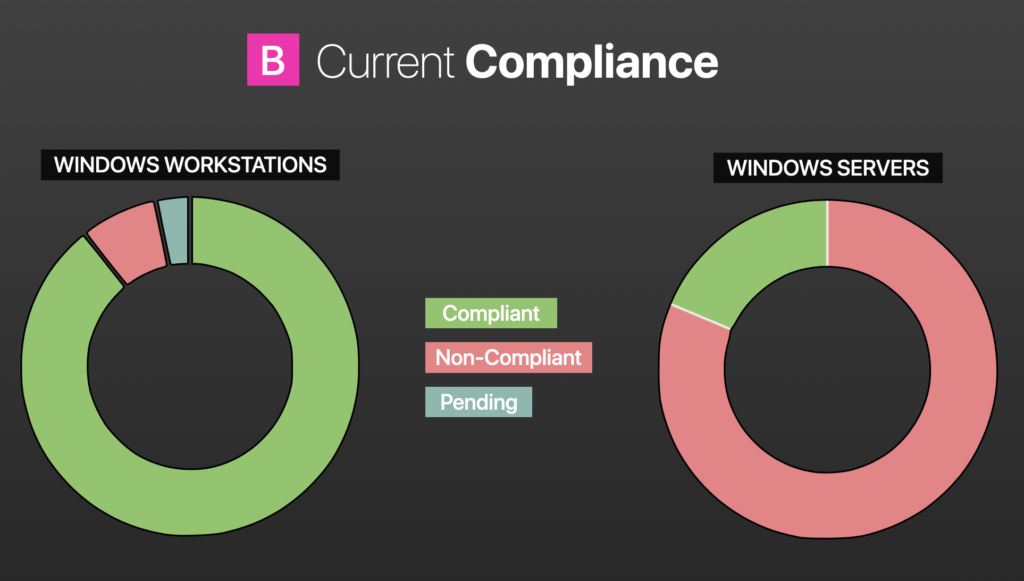
Then at the 30,000-foot view, with the same definition of compliance, no outstanding, non-superseded, critical, or important patched in excess or date of release over 30 days.
What can we glean from this?
First, get lean to get fast. What does this mean?
The traditional paradigm won’t allow anyone to be responsive enough to respond or keep pace with the volume of threats that are coming in.
We need to reduce the number of niche agents that we run on endpoints. One agent may do something extremely well for just one subset, and we have 15 of them on our endpoints, so we think we’ve covered all the niches. But what are we doing with all of the data that those are providing?
Is collecting all that data actually making our endpoints more secure? Where are we aggregating that data? How are we correlating it? How are we responding to it? The bottom line is: it’s not really helping.
A better solution is to aggregate your human capital. Don’t fire people; instead, do the next best thing, fire vendors. It makes your endpoints less clunky.
Fewer tools is simpler. Fewer contracts to stay on top of. What are you really getting out of them?
We’ve found far more success in one month using an endpoint agent that allowed the flexibility to scan, patch, update software, and remove software than we ever did from complex and elegant workflows and processes made to disseminate reports. Using SCCM, Jamf, Ansible, or Red Hat Satellite—we’ve never seen trend lines nosedive like that.
Speak in the same language in the same tool to collaborate in more of a near-real-time fashion about responding to threats.
There’s always a bunch of people who will say: “Scott, this doesn’t apply to me because I’m really good at so-and-so,” or, “you don’t understand I can’t patch, I can’t put an endpoint agent on all of my clinical engineering devices.” Since tools aren’t solutions, it’s time to get really comfortable with tradeoffs.
Maybe there are certain things that a more all-encompassing, multifunctional agent doesn’t do as well in a certain discipline or a specific area that a niche tool does.
Do you see the benefits of that?
Do your trend lines and compliance numbers look as good as those or better?
Is that a tradeoff you might be willing to make?
Maybe we don’t cover every niche with every tool from every vendor that gave a quick brief on how their products will solve our problems. Maybe that’s going to give a better efficacy rate.
Second, be brilliant at the basics. I really can’t say this enough.
Chasing zero-days, putting together tiger teams to go after the next WannaCry. I don’t know if I’ve seen a tiger team run and then say: “We’re done. We can disband the team; we have fully remediated. There is no more WannaCry in our environment.” We’ve just never seen it happen.
They kind of fizzle out. Then everyone has an excuse as to why they can’t patch this system or that system.
Apply missing patches. Update your software. Remove software you don’t need.
There are tools out that do all of that, and you can deploy software and find out what and how often your software is being used and can see, just in terms of sheer attack surface reduction, where you can cut licensing. No one likes to spend extra money.
But be brilliant at the basics so that when the next Follina comes out (that’s not a missing patch, it’s not a piece of software you can just update—it’s a registry key) you’ll be ready.
With the right endpoint agent, you can have that registry key deleted, but you will be much more poised to respond to a threat that falls outside of the box if you have basic cyber hygiene that you install and you have attained and maintained patch compliance, and you stop running legacy software.
Be aggressive. If somebody wants to say, “I can’t patch this system because of…”
I don’t care.
“But what about the user experience? If I patched….” What user? This is not a hotel; we’re not in the end-user experience game.
This would never happen in our organization, you would never see any pink in the chart. You don’t see anything. Our numbers couldn’t be put in the right format quickly enough, but it’s all green, and our mean time to patch is about 2 ½ days. Our mean time to update software is about 3 ½ days. There are many reasons for this.
While you may be thinking I can’t do that. We understand, we all have to work within the boundaries of our industry vertical, our network, our capabilities, etc.
First and foremost, the reason you would never see this is that our CTO would simply not allow it to happen. So, be aggressive. Start asking the question “why” more and probe more deeply.
Why haven’t we patched the servers? Well, you mean you don’t understand that if one of these goes down during patching, it’s going to take X amount of time to fix.
How often does that happen? What’s the likelihood of it happening? Give me an actual compelling reason.
I want to know why this system isn’t patch compliant.
It’s simple, really. This is what our organization’s goal is. We are going to improve our overall cyber hygiene, and I’m going to hold you to it.
Being aggressive or, at minimum, being an advocate at the table when folks are making those security requirements versus business requirements or operational requirements decisions—there’s some voice in there that says: “Why are we not doing this, and why are we so slow? Do we need to be testing this long? Does this server really need to have over 100 missing patches on it?”
Sometimes the answers may be good. They may be well within your business’s risk tolerance. But often, they’re not, and there’s something you can do about it if you get aggressive.
The author
Scott Savenelli is the Manager of Vulnerability Management & Patching Services at Novacoast. He works with organizations of all sizes and industry verticals to build and optimize their vulnerability, patch, risk assessment, and perimeter security programs. This article was translated from his presentation at the 2022 Innovate Cybersecurity Summit in Scottsdale, AZ.

